Afin de analyser nos corpus sur ITrameur, il nous reste un dernier traitement à faire sur nos textes bruts extraits : la concaténation.
Il s’agit de rassembler, pour chaque langue, tous les textes extraits dans un fichier. Chaque texte devrait être balisé afin de pouvoir se distinguer l’un de l’autre.
Bien évidemment, nous n’allons pas copier et coller chaque texte à la main! Voici la ligne de commande qui permet de réaliser ce traitement en 2 minutes.
for file in ls seg_1-*; do echo « <partie=$file> » >> corpus_dump_zh.txt; cat $file >> corpus_dump_zh.txt; echo « </partie> » >> corpus_dump_zh.txt; done;
Ainsi, tous nos textes chinois segmentés dans le répertoire DUMP sont rassemblés dans le fichier « corpus_dump_zh.txt ». Nous faisons également le même traitement pour les textes en français et en anglais, ainsi que les textes dans le répertoire CONTEXTES.
Un petit plus :
Supprimer les mots vides (stop words) avec python.
Un mot vide désigne un mot non significatif figurant dans un texte. En français, des mots vides pourraient être « de », « le », « ce »…
Etant donné que nous ne sommes pas certains de l’utilité de ce type de mot dans nos textes, nous avons décidé de générer une deuxième version de textes concaténés en enlevant ces mots vides. Ainsi, au moment de l’analyse, nous pourrons utiliser l’une ou l’autre version selon nos besoins.
Voici un petit script python que nous avons utilisé pour supprimer les mots vides :
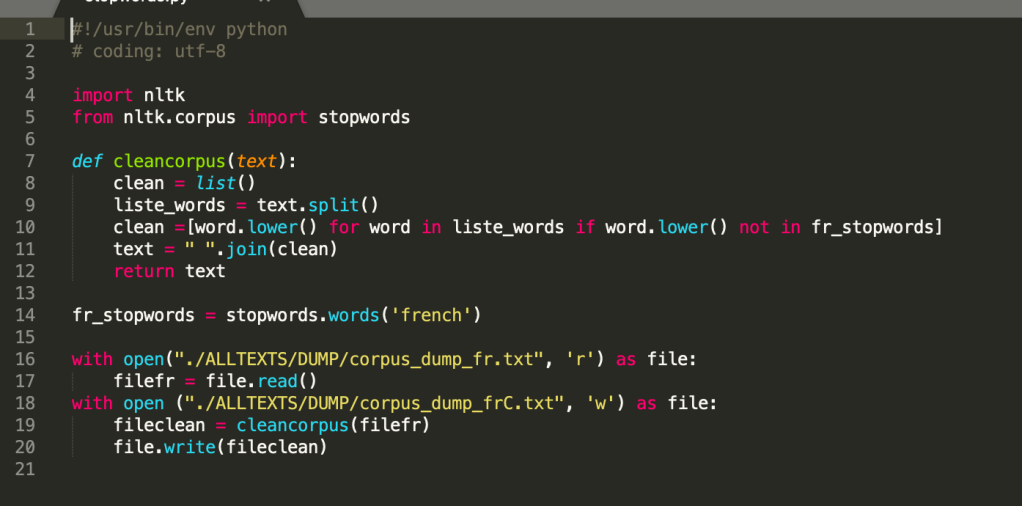
Les listes de mot vides que nous prenons comme références sont :
Pour l’anglais et le français: Les listes fournis par la bibliothèque NLTK
Pour le chinois: cn_stopwords.txt (https://github.com/goto456/stopwords)
