Afin de bien analyser les corpus que nous avons collectés pour la réalisation du projet, nous avons tout d’abord besoin d’un script qui permet de : .
Traitements principaux
Sauvegarder les urls dans des tables html.
Récupérer les code https de chaque url
Récupérer l’encodage de chaque url
Sous traitements
Extraire le texte brut de chacun des urls.
Calculer les occurences des motifs choisis.
Extraire les contextes autour des motif choisi.
Calculer l’index hiérarchique de chaque dump
Calculer la fréquence des bigrammes de chaque dump.
Nous allons donc présenter étape par étape, la réalisation de notre script ainsi que les problèmes rencontrés.
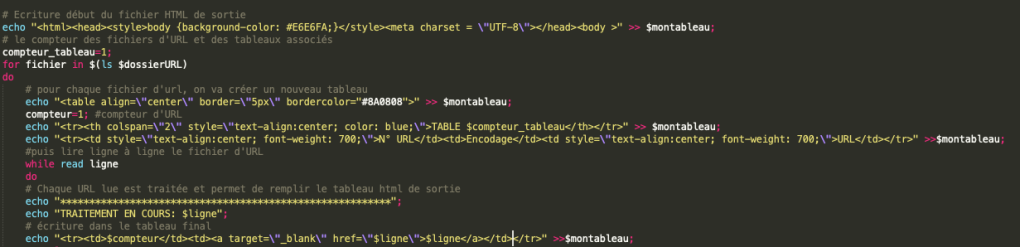
I. Ecriture des urls dans des tables html.
Nous avons besoin de créer trois tables car chaque table est utilisée pour sauvegarder des urls d’une langue donnée.
Nous utilisons la boucle « for » pour lire chaque fichier url et chaque url ligne par ligne, ensuite les écrire dans les tables.
Voici le script :
II. Vérification de codehttp
Maintenant, il faut vérifier si les codehttps de nos urls sont bels et bien « 200 »(OK, requête traitée avec succès), ou du moins « 3xx » (Redirection) pour que nous puissions continuer les traitements.
Deux méthodes sont possibles pour obtenir le codehttp d’une url:
- avec « curl » : curl lien_url -w %{http_code}


Voici le code http « 200 » pour l’url « Le Monde ».
2. avec « httpstat » : httpstat « lien_url »
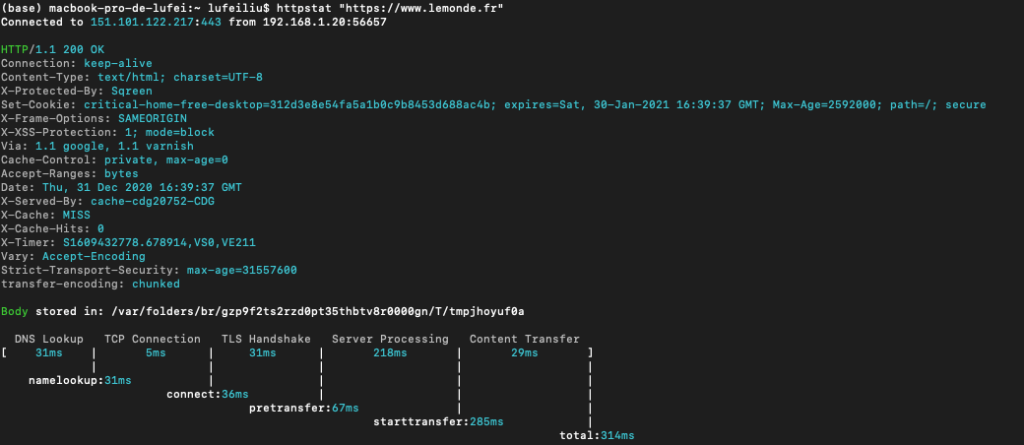
L’outil « httpstat » permet de visualier le contenu récupéré par « curl » d’une manière plus claire et concise. On peut l’utiliser en appelant le script python » httpstat.py » ou en appelant tout simplement » httpstat » sur la ligne de commande.
Pour plus de détails sur cet outil : https://github.com/reorx/httpstat
Dans notre script, nous avons choisi d’utiliser la commande « curl » car l’option « -o » permet de sauvegarder les contenus « aspirés » de chaque url dans un fichier html. De plus, l’option « -L » du « curl » permet de vérifier le bon fonctionnement des pages redirigées. Si votre objectif est d’avoir un aperçu rapide des informations sur votre url, « httpstat » est peut-être un meilleur choix.
Ainsi, nous avons ajouté cette ligne de commande dans notre script :
codehttp=$(curl -L -o ./PAGES-ASPIREES/ »$compteur_tableau-$compteur ».html $ligne -w %{http_code});
Les valeurs http_code sont stockées dans la variable « codehttp » et les pages html sont stockées dans le répertoire PAGE-ASPIREES.
Pour les urls qui renvoient un code 403 ou 404 etc. Tant pis, ils sont inutiles !
Pour connaitre les significations de différents code http, voici un lien vers wikipédia :
https://fr.wikipedia.org/wiki/Liste_des_codes_HTTP
III. La récupération de l’encodage.
Désormais, il faut extraire l’encodage des urls valides. Selon la valeur de l’encodage, différents traitements sont envisagés.
- Si l’encodage d’url est utf-8, on poursuit les traitements prévus (calcul des occurences des motifs, calcul de l’index hiérarchique, etc).
- Si l’encodage est non vide et non utf-8, vérifier si l’encodage est connu de « iconv ». Si oui, poursuivre les traitements prévus.
- Si l’encodage est non vide et inconnu par « iconv » -> on ne fait rien.
Avec l’outil « httpstat », on obtient facilement l’information sur l’encodage de l’url.

Ensuite, on peut utiliser « egrep » pour extraire la valeur de l’encodage et la stocker dans une variable.

Autrement, si l’encodage n’a pas pu être extrait avec httpstat, on peut utiliser l’outil « detect encoding » pour parvenir à cette fin:
On sauvegarde l’exécutable de l’outil dans le répertoire PROGRAMMES, puis avec la commande suivant, on peut détecter les http_code de chaque fichier html sauvegardé dans le répertoire PAGES-ASPIREES.
for file in $(ls ./PAGES-ASPIREES/); do ./PROGRAMMES/detect-encoding-osx ./PAGES-ASPIREES/*.html; done;
On a donc intégré cette ligne de commande dans notre script :

Passons maintenant aux sous traitements :
IV. Extraction de textes bruts
Deux outils ont été utilisé pour cette extraction : lynx et Readability-Cli. (Les différents entre ces deux outils seront expliqué à part)
lynx a été utilisé pour l’extraction à partir des urls chinois encodé en utf8, Readability-Cli a été utilisé pour le reste des urls.
Voici les lignes de commandes :
lynx -dump -nolist -assume_charset= »UTF-8″ -display_charset= »UTF-8″ ./PAGES-ASPIREES/ »$compteur_tableau-$compteur ».html > ./DUMP-TEXT/ »$compteur_tableau-$compteur ».txt;
readable ./PAGES-ASPIREES/ »$compteur_tableau-$compteur ».html -p text-content > ./DUMP-TEXT/ »$compteur_tableau-$compteur ».txt;
V. Calculer les occurences des motifs choisis
L’expression sur laquelle on travaille est « mouvement social » et elle peut être traduite en anglais soit par « social movement » soit par « industrial action ». Sa traduction chinoise s’écrit comme « 社会 运动 » (chinois simplifié) ou bien comme « 社會 運動 »(chinois traditionnel)
Etant donné que en fraçais comme dans les deux autres langues, cette expression est composé de deux mots. Afin de mieux cerner la recherche de motif, on a décidé d’enlever l’espace, c’est-à-dire considérer cette expression comme une seule séquence. Cette étape peut se réaliser en intégrant la commande « sed » au moment de la segmentation des textes chinois et de l’extraction de textes français et anglais.
La commande s’effectue ainsi :
sed -e « s/社会 运动/社会运动/g » -e « s/社會 運動/社會運動/g »
sed -e « s/social movements/socialmovements/g » -e « s/industrial actions/industrialactions/g » -e « s/mouvement social/mouvementsocial/g » -e « s/industrial action/industrialaction/g » -e « s/social movement/socialmovement/g » -e « s/mouvements sociaux/mouvementssociaux/g »
Notre motif choisi est donc : mouvement|socialmovements|industrialactions|socialmovement|industrialaction|mouvementsocial|mouvementssociaux|社會運動|社会运动
Pour calculer la fréquence du motif dans chaque fichier dump, voici la commande :
compteurmotif=$(egrep -o -i $motif ./DUMP-TEXT/ »$compteur_tableau-$compteur ».txt | wc -l);
VI. Extraction du contexte autour du motif
Ici, on utilise « egrep » pour extriare le contexte au format txt et l’outil « minigrep » pour extraire ceux-ci au format html.
La commande « egrep » :
egrep -C 2 -i « $motif » ./DUMP-TEXT/seg_ »$compteur_tableau-$compteur ».txt > ./CONTEXTES/ »$compteur_tableau-$compteur ».txt;
Avec cette commande, nous obtenons les deux lignes précédant et suivant le motif de chaque dump texte ( texte segmenté pour le chinois), et on sauvegarder chaque fichier contexte dans le répertoire qui lui est réservé.
L’outil « minigrep » :
Je remercie tout d’abord l’auteur de ce blog. Etant utilisatrice de Macbook, son tutoriel sur l’installation de minigrep sur Mac m’a beaucoup aidé. (lien vers tuto : https://pluritaladoption.wordpress.com/2018/12/03/installation-de-minigrep-sous-macosx/)
Peut-être une mini contribution:
Pendant l’exécution, j’ai rencontré cet erreur
xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools),
missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
J’ai pu résoudre le problème en installant Xcode toolkit
$ xcode-select --install
Revenons donc sur la commande pour appeler minigrep:
perl ./PROGRAMMES/minigrepmultilingue-v2/minigrepmultilingue.pl « UTF-8″ ./DUMP-TEXT/seg_ »$compteur_tableau-$compteur ».txt ./PROGRAMMES/minigrepmultilingue-v2/motif-2020.txt ;
mv resultat-extraction.html ./CONTEXTES/HTML/ »$compteur_tableau-$compteur ».html;
minigrep génère à chaque fois un fichier html qui est nommé par défaut « resultat-extraction.html ». Il faut penser à déplacer ces fichiers dans le répertoire CONTEXTES en lui donnant un nouveau nom. Personnellement j’ai crée un sous-répertoire nommé « HTML » afin de sauvegarder tous les fichiers généré par minigrep.
VII. Calcul de l’index hiérarchique
Cet étape permet de sauvegarder dans un fichier la fréquence de mots de chaque dump par ordre décroissant.
egrep -i -o « \w+ » ./DUMP-TEXT/utf8_ »$compteur_tableau-$compteur ».txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/index_ »$compteur_tableau-$compteur ».txt ;
egrep -i -o : ne pas tenir de compte de la casse et afficher seulement le motif recherché
sort -r -n : trier les résultats en fonction de la valeur numérique par ordre décroissant.
sort -s : stabliliser l’ordre du résultat
sort -k 1,1 : spécifier le ou les champs à prendre en compte en tant que critère de tri, en l’occurence premier champ.
uniq -c : compter la fréquence du résultat
VIII. Calcul de la fréquence des bigrammes
tr » » « \n » < ./DUMP-TEXT/utf8_ »$compteur_tableau-$compteur ».txt | tr -s « \n » | egrep -v « ^$ » > index1.txt ;
La commande tr » » « \n » permet de remplacer les espaces par un « retour à la ligne, ainsi les mots sont affichés ligne par ligne. tr -s « \n » permet de garder un seul retour à la ligne en cas de répétition. « egrep -v » permet d’enlever le motif donné.
tail -n +2 index1.txt > index2.txt;
on crée un autre fichier index à partir de l’index1.txt en enlevant le premeier mot.
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/bigramme_ »$compteur_tableau-$compteur ».txt ;
On colle les deux fichiers index ensemble et répéter la précédure de tri utilisé pour le calcul de l’index hiérarchique, ce qui donne en résultat une liste de bigrammes trié par fréquence par ordre décroissant.
Voici une structure général de notre script :
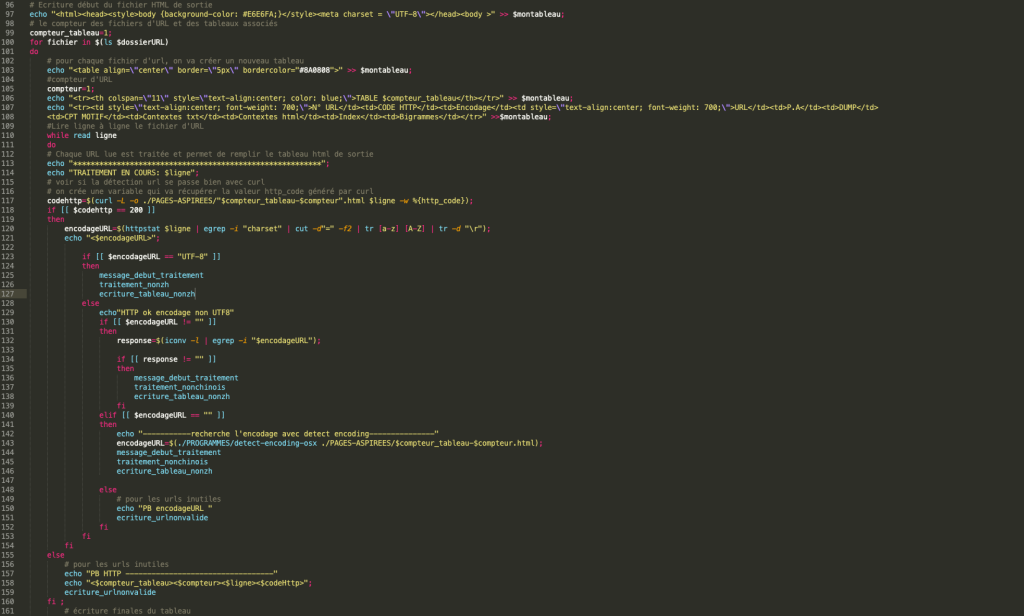
Les fonctions ont été utilisé pour factoriser les traitements répétitifs, nous allons expliquer ceci dans un autre article.
